The comment spam filter for this blog is not perfect so I usually skim through the spam comments to see if it caught something legitimate. Sometimes the comments can be quite amusing, like this one:
On so many levels, I am more more offended by the “generic commenter” than I am by the more obvious spammer. Why? at least the obvious spammer is completely open and honest about their spamming!
We know who they are. The so called generic commenter is a cheat and a charlatan. You can probably see that I have very strong opinions toward this group of people
Here is a quick tip if you are having slow performance with Linux running on VirtualBox:
Assign at least two processors to the Linux instance
Some background… My laptop came with Windows 7. I prefer to use Linux (currently Ubuntu) when developing and I really dislike dual-booting so installing Ubuntu side-by-side with Windows is not my preferred choice, mainly for two reasons:
I like to play games from time to time. Ubuntu is ok for this but Windows is still the winner.
Dell’s BIOS updates are released in .exe format and although I could probably run these from Ubuntu, I would not trust such critical updates to a non-native environment. Other drivers like graphics card drivers are also better supported in Windows.
So instead of replacing Windows or dual-booting I use VirtualBox to create a virtual machine environment for Ubuntu to run in. I have been running Ubuntu with 4GB of ram and 2 processors for a while now and it runs incredibly fast. For example, it boots in about 4 seconds.
Recently, I wanted to try out other Linux distributions such as Fedora, Debian, Xubuntu and Linux Mint and VirtualBox is perfect for testing. I gave each of these 1GB ram and 1 processor. They were all incredibly slow, even during installation. It felt like they ran more than 10 times slower than my Ubuntu installation. After thinking about it for a while, I tried simply increasing the processor count from 1 to 2 on each Virtual machine. Voila, they all had the same fast performance as my original Ubuntu installation. They are fast… very very fast!
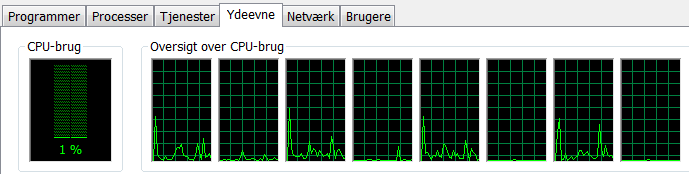
So why did the processor count matter so much? I do not really know how to dive in and test it but my theory is that assigning just one virtual processor in VirtualBox is like assigning just one thread of one processor, if your processor is made by Intel and has Hyper-Threading technology. As you can see below, Windows Task Manager shows 8 processors even though there are actually only 4 (I have an Intel Quad Core i7-3612QM) so Windows seem to think that I have 8 processors. I know, I know, of course Windows knows about hyper-threading but it still seems to treat each thread as an independent processor.
This post is about Antecons, a product recommendation engine, now part of Conversio. Antecons is no longer commercially available, but I have kept my developer diary on my website with permission.
The first data mining algorithm that was implemented for Antecons was Frequent Pattern growth (FP-growth) which is an algorithm that finds frequent patterns in transactional data such as shopping baskets. Finding frequent patterns is often a necessary step in finding association rules. An association rule is something like “if customers purchase beer, they also buy chips” or “if voter is African American, he/she votes for Barack Obama”. This information can be valuable to analyze patterns and act upon them, e.g. for marketing or reporting.
As mentioned earlier, the first prototype of Antecons was implemented in .NET and used FP-growth to find frequent patterns and association rules. The algorithm was executed in-memory on a single thread. This is fine for smaller datasets but it does not scale to larger datasets. When restarting Antecons, I decided to look at FP-growth again and solve the scaling issue. With the help of MapReduce and Google App Engine, the future is promising.
Before going into detail with the FP-growth and MapReduce, I will briefly give an example of association rule mining. The next section can be skipped if you are familiar with the concepts.
Association rule mining — a quick example
Consider the following dataset consisting of three shopping transactions:
t1 = Beer, Chips, Soda
t2 = Chips, Soda
t3 = Chips, Soda
From this dataset, we can find frequent patterns. A frequent pattern is a set of one or more items that occur together (frequently) in the dataset. When finding frequent patterns, the support is recorded along with the pattern. The support is simply a count of how many times a pattern occurs in the entire dataset. For the above dataset, we have:
Here, we have defined a minimum support of 1 which means that all patterns with support greater than or equal to 1 are considered frequent.
Based on the frequent patterns, we can construct association rules. As mentioned earlier, an association rule can informally be stated “If customers purchase Chips, they also buy Soda” or a bit shorter:
Chips -> Soda
Association rules have two basic metrics:
Support: How many times do all the items of a rule appear together in the entire dataset.
Confidence: How often does the left-hand side of the rule appear with the right-hand side.
Based on the frequent patterns from above, here are a few of the association rules we can construct from those patterns:
For more info on association rule mining, see the Wikipedia article for association rule mining.
The problem with association rule mining
Running FP-growth in-memory has certain limitations. To give an idea about the performance, numerous tests of FP-growth were carried out on the prototype of Antecons (when I write FP-growth, I really mean “FP-growth plus finding association rules” but I will just refer to the algorithm as FP-growth). A few of the results are graphed below (please read the caption under the graph).
FP-growth running time as a function of minimum support. Each line represents running times for 20 thousand transactions with 1-10 items in each transaction and either 50 or 200 unique types of items.Number of association rules as a function of minimum support. Each line represents rules found for 20 thousand transaction with 1-10 items for each transactions and either 50 or 200 unique types of items.
There are two problems here:
The running time increases as the support decreases.
The number of association rules decreases as the support increases.
If the goal is to achieve low running time and finding many rules, the above two problems create an unwanted trade-off between running time and number of rules found. In fact, even with 20000 transactions and only 200 unique types of items, 0 rules are found if the minimum support is 50 and only 24 rules are found with minimum support 25. In other words, out of 20000 transactions, it is not possible to find any itemset that occurs 50 or more times. This might be surprising but it actually illustrates one of the main problems with association rule mining:
In order to find interesting association rules, the minimum support for these rules has to be set sufficiently low, but when setting the support very low, the running time and memory usage explodes.
Scaling FP-growth with MapReduce
Some people say that you should not think about scale early on in a project. I agree to some extent but since the limitations of FP-growth start showing on fairly small datasets, it is relevant to consider if the solution can scale at all. When handling millions of transactions, it is no longer feasible to run FP-growth in-memory and on a single thread. Even if we assume that the algorithm scales linearly on the input set, a few minutes all of a sudden turns into a few days and keeping millions of rows in an in-memory data structure is probably not a good idea either.
Fortunately, there are ways to run FP-growth concurrently using a technique called MapReduce. MapReduce is a powerful method that is used extensively by e.g. Google for their search indexing. Google also provides an open source MapReduce framework for Google App Engine — very convenient for Antecons since I chose to deploy on the Google App Engine.
With no prior experience with MapReduce, I was lucky that someone has already implemented FP-growth for MapReduce in Hadoop. Since the basic FP-growth algorithm was implemented a year ago for the Antecons teaser, I just needed a basic idea of how to set up the mapper and the reducer so I chose an approach that is conceptually the same as the one mentioned in the blog post that I just referenced.
The MapReduce pipeline
The full pipeline for creating association rules with MapReduce is actually quite simple and is currently less than 250 lines of code. The first thing that happens is that a reader reads transactions and sends them in batches to the mapper. The map function looks like this:
def fp_map_transactions(transactions):
patterns = fpgrowth.fpgrowth(transactions)
for pattern, support in patterns:
yield pattern, support
After the map step, the MapReduce framework automatically groups together patterns that are the same in the shuffle step which is completely automated. The reduce function receives the pattern and a list of support counts for the pattern so all we have to do is sum the support counts to find the global support count for the pattern:
def fp_reduce(pattern, values):
support = sum([long(i) for i in values])
yield '%s:%s\n' % (pattern, support)
The patterns are yielded to a MapReduce writer that writes the result to the blobstore. After all the results have been stored, another pipeline starts finding the association rules for the patterns. The mapping function for this pipeline receives a pattern-support pair and looks like this:
def fp_to_association_map(line):
pattern, support = line.split(':')
yield pattern, support # Yield the full pattern
if len(pattern) > 1: # Yield every subpattern
for item in pattern:
others = [i for i in pattern if i != item]
yield others, line
Finally, the reducer puts all the things together to create the association rules.
def fp_to_association_reduce(left, values):
# Find value that is not a pattern-support pair
fullpattern_support = [value for value in values
if len(value.split(':')) < 2][0]
values.remove(fullpattern_support)
for value in values:
pattern, support = value.split(':')
for item in left:
pattern.remove(item)
confidence = float(support)/float(fullpattern_support)
rule = { 'left': left, 'right': pattern,
'sup': support, 'conf': confidence }
This works :-)
Initial observations about GAE MapReduce
The standard Datastore reader for the MapReduce framework reads one entity at a time so for step 1, I extended the built-in reader to return batches of transactions instead of just one transaction. Otherwise, FP-growth would run for each transaction in the datastore and that would be silly. The code for this reader is simple and can be found here nowhere (it is not valid as of 2013-05-04).
When starting a MapReduce pipeline on Google App Engine, it can be specified how many shards that the computations should be run in. Theoretically, if the number of shards are set to 16, the computations should run concurrently on 16 different threads. I could not reliably test this on the development server but for 1000 transactions, it took 5 minutes to run the frequent pattern pipeline using 4 shards and 1 minute using 16 shards. This sounds good enough but the framework was reporting that it was only using one of the shards for all computations so the difference in running time is strange. Later, I got the work evenly distributed over all shards and the strange behavior disappeared.
Without much optimization, it currently takes between 1 and 2 minutes to analyze 1000 transactions on 16 shards which is not impressive compared to the in-memory version that could analyze 50000 transactions in 40 seconds but I have not carried out any tests on much larger datasets to see if the MapReduce framework scales. That is next step.
The MapReduce framework for Google App Engine is certainly a great help for easy parallelization of heavy work and I look forward to testing it out more to find out, if it is a good option for more data analysis algorithms.
This post is about Antecons, a product recommendation engine, now part of Conversio. Antecons is no longer commercially available, but I have kept my developer diary on my website with permission.
On Friday, October 5, 2012, Antecons was started over from scratch and another journey begun. How long this journey will be and what will happen is uncertain. But here are some initial notes on the progress.
Where to begin
Starting out is often a bit slow, mostly because lots of questions pile up. Like what programming language to use and what platform to deploy on. What about project management, bug tracking and early documentation? It is easy to get caught up in those things and it happened to me as well on the first day. I was inspired when I read that Jeff Atwood does not make TODO lists. However, writing down a few ideas and making some mental notes works well for me to get a feel for what I want to do with Antecons. But TODO lists might not be useful and micromanaging a project for a one-person team in the exploratory/early phase is definitely not worth it.
So I ditched the project management for now, I have no bug tracker and the documentation I wrote initially is already outdated. When will I ever learn. Instead of wasting more time, I made decisions. Use Python, deploy on Google App Engine and start making a simple web-based API using JSON for data representations and then take it from there.
To REST or not to REST
REST (Representational State Transfer) is an interesting choice of architecture for web-based APIs. REST is kind of a buzzword and most REST APIs are not actually RESTful according to Roy Fielding who coined the term. So of course, I decided that my API would be truly RESTful. Alas, the choice of JSON for data representation makes it difficult to make a hypertext-driven API since there are no widespread standards for how links should be represented in JSON, unlike e.g. the very precise definitions in the Atom Syndication Format (an example is this blog’s Atom feed ).
There is a specification draft called JSON schema that is very promising so I decided to try and use it for the API. A very crude first alpha version of the API was actually fully hypertext-driven based on the principles outlined in JSON schema and all data representations were described by a JSON schema. Using JSON schema has two advantages:
It provides a way to validate data both on the client and server side.
It is cool to be RESTful.
Ok, so while number one is useful, number two is kind of silly. And actually I think it is ok to not be truly RESTful but still use some of the REST principles to build an API. My favorite example right now is the Google Calendar API which uses resources for data representation and HTTP verbs to interact with these resources but is not hypertext-driven. According to the Richardson Maturity model, it is probably level 2 REST — if there is such a thing. With Antecons, this is the level of REST I am aiming for.
So what about JSON schema? Well currently, I am making a JSON schema for all data representations in Antecons but I have not decided whether or not I should continue this trend. If using JSON schema means that some code can be autogenerated by the client then that is fantastic. But I do not know of any ready-made tools to do that, such as is the case for e.g. WSDL in Visual Studio.
Progress
After this Friday, I should have another crude alpha version ready for publishing. After it is out there, I will write about it here. The API cannot do much right now. You can just upload some simple data and view it. Basic basic stuff. But I also hope to have the first data analysis algorithms ready within the near future. Then it starts getting exciting.
This post is about Antecons, a product recommendation engine, now part of Conversio. Antecons is no longer commercially available, but I have kept my developer diary on my website with permission.
In part 1 of the Antecons developer diary, I wrote about what stalled the development of Antecons a year ago. It was a combination of a lack of time and a lack of vision. In this post, I will elaborate on the problems I ran into and how I intend to tackle them (or not) this time.
The ideal scenario
To reiterate from my last post, the ideal scenario for getting Antecons to work with a webshop looks like this:
User registers for Antecons and receives a unique User ID.
User inserts 10 lines of Javascript code in the header of each webshop page where Antecons should show recommendations.
Antecons takes care of the rest and starts showing recommendations on the user’s webhsop.
There are two major problems with this approach: How do we get the data foundation and how do we automatically show the recommendations.
The data foundation
The recommendations of Antecons are supposed to be based partly on previous purchases in a webshop. But how can Antecons gather sales data for the data foundation. I can think of a few solutions:
Send sales data to Antecons in batches.
Send sales data to Antecons the moment a purchase is made.
Have Antecons fetch sales data from a tracker that is already set up, such as Google Analytics.
All of the above require some action from the user and thus deviate from the ideal scenario. The first two require implementation on the webshop before using Antecons. The third also requires implementation on the webshop but in an earlier step, i.e. when setting up Google Analytics.
Besides sales data, the data foundation would probably also consist of data about each product, such as product name, description, image and product page url in order for Antecons to automatically show recommendations. Some of the options from above also apply here. We could:
Send product data to Antecons in batches.
Send product data to Antecons the moment a product is created/changed.
Create a web crawler that extracts product data from the webshop.
The first two options are basically the same as listed earlier. The third option, however, has some potential, especially if the product pages are nicely marked up with appropriate tags, classes or similar that could tell a crawler something about the data. For example, a crawler could be set up to look for the following elements:
<img class="product-image" src="images/a-fine-image.jpg" />
<span class="product-name">Nice product</span>
<div class="product-description">It has good features.</div>
<span class="product-price-single">42</span>
If the crawler regularly searched through the webshop, the user would not have to update their product catalogue themselves.
The presentation
Let us assume that we have the data foundation. Now, we need to show recommendations on the user’s webshop. But how can Antecons know where to show recommendations on e.g. a product page if the recommendations are shown completely automatic from a piece of Javascript code. It seems it would require at least some user action. To make it simple for the user, maybe the user can just create sections of a page where Antecons is allowed to show recommendations. These sections could be marked like this:
<div class="antecons-recommendations"></div>
Antecons could then insert recommendations in these sections. There is a problem though. What about products that change pictures, prices, urls and so on? How can these changes be reflected automatically by Antecons with immediate effect: Well, they cannot, unless the Antecons data is updated at the same time as the user data is updated. Perhaps a web crawler could help in this regard, as mentioned in the previous section but it might not be the best way to do it.
The “solution”
In software development, there is rarely a perfect solution to a problem. So I have decided to step back and say: The user probably has to do some initial work to get Antecons up and running and that is ok. Instead of focusing so much on the initial setup, I will try to make an API that is easy to use, fast and provides good data analysis possibilities. First, it makes sense to construct a minimal viable API for Antecons. This API would provide the following:
A way to send transactional data to Antecons (e.g. sales data).
A way to fetch recommendations for a single item.
And that is basically it and what I am currently working on. After that, we can iterate. I have not shelved the idea of having a crawler and I have not shelved the idea of having some simple Javascript code to do a lot of the work for the user. But it might be that a better option is to write some plugins for popular e-commerce systems such as Magento, Shopify and others. As I just said: We can iterate. This is just the beginning.