Since I posted the first Oregon 💚 image half a year ago, a lot has happened in the image generating world.
I got access to DALL-2 some months ago, but didn’t bother to blog about it. I did include some DALL-2 generated images in some of my AI Tales, e.g. Doge at The Cataract.
Stable Diffusion is now the latest thing everyone is talking about, partly because it is much more accessible than DALL-E 2. It produces better results than VQGAN+CLIP and runs flawlessly on my consumer GPU from 2019. I use a web UI developed by sd-webui to generate images, and it has become my go-to for image generation. For example, Stable Diffusion created a compelling image for the latest installment of the Assandra & Capybara series.
Anyway, I thought it would be appropriate to see what comes out of the “Oregon 💚” prompt with Stable Diffusion. The headlines below correspond to the prompt used, and I spent very little time curating the images.
I am blown away by VQGAN+CLIP, a pair of neural network architectures that can be used to generate images from text. When I wrote my previous post on “A game of AI telephone“, it was not clear to me yet how exciting this technology actually is. Or rather, I had not used the right text prompts yet.
To generate an image, the input text can be written in a way that both changes the content and the style of the generated image. The neural networks don’t always produce photo-realistic and coherent output, so if we only describe content, and not style, the results often look distorted or end up in uncanny valley, especially when depicting people or animals.
For example, these images of “border collie puppies” are not very nice:
Two VQGAN+CLIP outputs for the prompt “border collie puppies”, after 500 iterations.
However, playing around with the words in the text input can yield very different results. “Finding the right text” even seems to have led to a new term called “prompt engineering”. Although it is the neural networks doing all the hard work of generating images, combining the right words to produce interesting outcomes is almost an art in itself.
Modifying the above “border collie puppies” example to include a setting (hill) and style (painting) already produces more interesting outputs on the first try:
Prompt: “a painting of a hill with a border collie puppy standing on top looking at the sunset”
The keyword “painting” is part of the reason that the images look like actual paint strokes. The border collie dog is still not looking very good, but because the final image is a bit more abstract, it does not matter so much.
Changing “painting” to “pencil drawing” gives slightly different results. Notice that the texture is less paint-brush and more pencil-like (if you squint a little), and we also get what appears to some sort of text (no idea why):
Prompt: “a pencil drawing of a hill with a border collie puppy standing on top looking at the sunset”
This way of changing the prompt slightly is quite fun (and time consuming), and people have come up with all sorts of tricks. I am, for example, quite fascinated by the “cyberpunk” aesthetic which I first saw from Rivers Have Wings as well, although that example is using a different generator than VQGAN.
Cyberpunk does not seem to work very well for the existing border collie prompt though, at least not without further tweaking:
Prompt: “a hill with a border collie puppy standing on top looking at the sunset | cyberpunk drawing”. The “|” character actually creates two prompts.
It works better for cities:
Prompt: “a spaceship flies over the neon-lit skyscrapers|cyberpunk”
You can probably see where this is going: Down a rabbit-hole of experimentation.
At this point, it is worth backtracking a bit and mention that there are still simple input prompts (without a specified style) that produce fun outputs. Here are two examples of “a unicorn”:
Prompt: “a unicorn”. Let’s be honest, we don’t really know how unicorns look, so who can say these are wrong :-)
But to me, the most fun comes from using slightly longer texts to see what comes out of it.
One idea I am playing around with is to take text from other sources and see what the networks come up with. For example, how about the legendary, somewhat-improvised, “tears in the rain” monologue from Rutger Hauer in Blade Runner. To jolt your memory:
I’ve seen things you people wouldn’t believe. Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhäuser Gate. All those moments will be lost in time, like tears in rain. Time to die.
Roy Batty / Rutger Hauer – Blade Runner
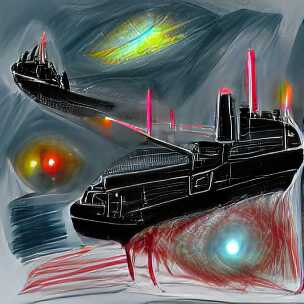
If there was ever a quote that deserved to be illustrated, it is this one. Let us try it, but only include the middle part, i.e. “Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhäuser Gate”:
Image generate from the tears in the rain monologue from Blade Runner
Ok, well, that’s not really coherent is it? It looks like a collage of a battle ship, laser beam, fire, water and starry sky just mixed randomly together. A bit disappointing, but as I mentioned above, the style is often quite important.
And looks what happens when we simply add “science fiction painting” to the prompt:
Image generate from the tears in the rain monologue from Blade Runner, in the style of “science fiction painting”
Wow, that is quite different. Personally, I find this very satisfying to look at. I would probably even hang one of these on my wall!
As a side-note, I often find the outputs of the early iterations quite interesting to look at as well. The above images are from the 500th iteration of the generation, but already after 50 iterations, they both have a certain artistic quality to them, especially the second one which I like better than the final output (look at those colors!):
After just 50 iterations of the tears in the rain monologue, the images are already interesting and look quite different form the final output.
Roy Batty was an AI right? What if we take a modern-day “AI” and produce some text, then use this as a prompt to our image generator.
Using the gpt-neo-1.3B text generator with the text seed “The sky”, here are two example outputs:
The sky was like a black cloud, and a man was standing there, his eyes blue and staring.
gpt-neo-1.3B with seed text “The sky”
The sky was clear. A blackbird had come, had flown into the room and was now looking up at the ground.
gpt-neo-1.3B with seed text “The sky”
In both cases, I added “painting” as style since that seem to work quite well in general.
Images generated from AI-generated text
Ok, so it chose to ignore the “man was standing there” part but at least it generated an eye surrounded by blue. And it depicted a black cloud and clear sky in both cases, as well as the outline of a blackbird.
All I did here was come up with “The sky” and through a series of steps, the neural networks did the rest. This idea of almost 100% AI generation of related text and images is quite fascinating to play around with.
On that note, I will end the post here and continue down the rabbit-hole for a bit longer. Here are two renditions of “a drawing of me going down a rabbit-hole” and two where I added “psychedelic surrealism” to the prompt, because why not.
Prompt: “a drawing of me going down a rabbit-hole | psychedelic surrealism”
Goodbye.
(All the images in this post are generated using default settings from this generator script. They are not hand-curated, i.e. they represent more-or-less the first output for each of the prompts. With a bit of curation, and experimentation, your results will be much better, as demonstrated by other authors.)
Neurons Spike Back (https://neurovenge.antonomase.fr/) was featured in the latest data science weekly newsletter. I would normally pass on such long articles, but the history of AI is interesting, so I gave it a shot. Reading the paper felt like a marathon, and I only completed it through sheer force of will, lots of coffee, and because it is cold and raining outside.
The article is very difficult to read (at least for me), not because it is filled with theory, but because the language is dry and academic, and it tries to condense decades of history around the research of AI into a fairly short (given the topic) article that discusses two opposing sides of research and thought: connectionist and symbolic AI.
Despite my warning above, if you have the patience, I found it to be a fairly good overview of how we ended up where we are today with deep learning dominating the state of the art for AI in many fields.
I found it particularly interesting to learn about the Mark I, a hardware neural network constructed during the 1960’s for simple object recognition. It is a good reminder that the concepts we are using today have been around for a very long time, and I often find that knowing a bit of the history behind them help understand what we are doing in the present.
Whenever there is a new announcement or breakthrough with AI, it always strikes me how out of reach the results would be to replicate for individuals and small organizations. Machine learning algorithms, and especially deep learning with neural networks, are often so computationally expensive that they are infeasible to run without immense computing power.
As an example, OpenAI Five (OpenAI’s Dota 2 playing bot) used 128,000 CPUs and 256 GPUs which trained continuously for several months:
In total, the current version of OpenAI Five has consumed 800 petaflop/s-days and experienced about 45,000 years of Dota self-play over 10 realtime months.
Running a collection of more than a hundred thousand CPUs and hundreds of GPUs for ten months would cost several million dollars without discounts. Needless to say, a hobbyist such as myself would never be able to replicate those results. Cutting edge AI research like this has an implicit disclaimer: “Don’t try this at home”.
Even on a smaller scale, it is not always possible to run machine learning algorithms without certain trade-offs. I can sort a list of a million numbers in less than a second, and even re-compile a fairly complex web application in a few seconds, but training a lyrics-generating neural network on less than three thousand songs takes several hours to complete.
Although a comparison between number sorting and machine learning seems a bit silly, I wonder if we will ever see a huge reduction in computational complexity, similar to going from an algorithm like bubble sort to quicksort.2
Perhaps it is not fair to expect to be able to replicate the results of a cutting edge research institution such as OpenAI. Dota 2 is a very complex game, and reinforcement learning is an area of research that is developing fast. But even OpenAI acknowledges that recent improvements to their OpenAI Five bot are primarily due to increases in available computing power:
OpenAI Five’s victories on Saturday, as compared to its losses at The International 2018, are due to a major change: 8x more training compute. In many previous phases of the project, we’d drive further progress by increasing our training scale.
It feels slightly unnerving to see that the potential AI technologies of the future are currently only within reach of a few companies with access to near-unlimited resources. On the other hand, the fact that we need to throw so many computers at mastering a game like Dota should be comforting for those with gloomy visions of the future :-)