I am blown away by VQGAN+CLIP, a pair of neural network architectures that can be used to generate images from text. When I wrote my previous post on “A game of AI telephone“, it was not clear to me yet how exciting this technology actually is. Or rather, I had not used the right text prompts yet.
To generate an image, the input text can be written in a way that both changes the content and the style of the generated image. The neural networks don’t always produce photo-realistic and coherent output, so if we only describe content, and not style, the results often look distorted or end up in uncanny valley, especially when depicting people or animals.
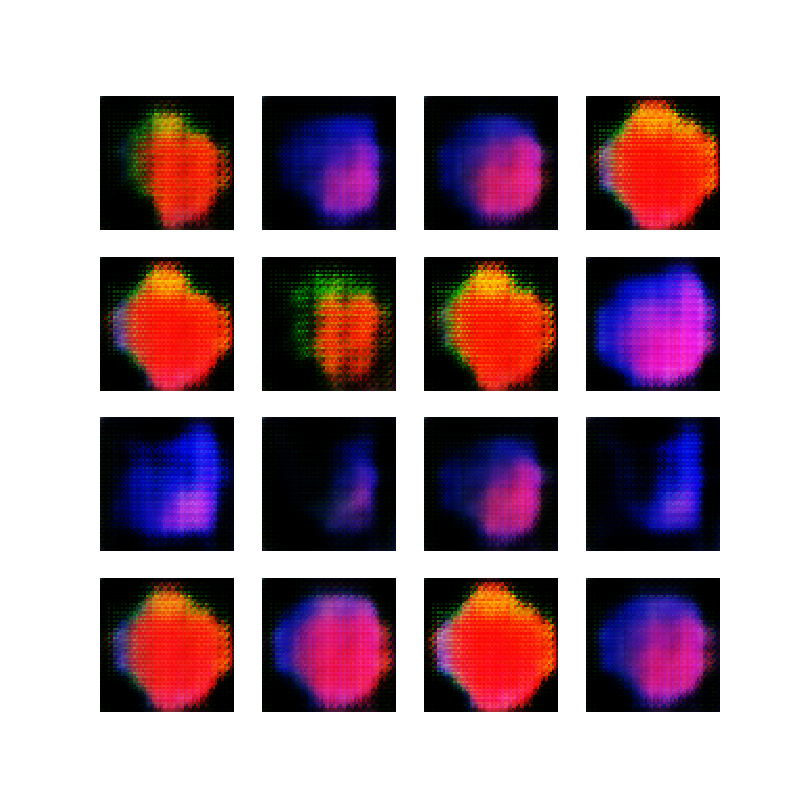
For example, these images of “border collie puppies” are not very nice:


However, playing around with the words in the text input can yield very different results. “Finding the right text” even seems to have led to a new term called “prompt engineering”. Although it is the neural networks doing all the hard work of generating images, combining the right words to produce interesting outcomes is almost an art in itself.
The Twitter account Rivers Have Wings1 has many amazing examples.
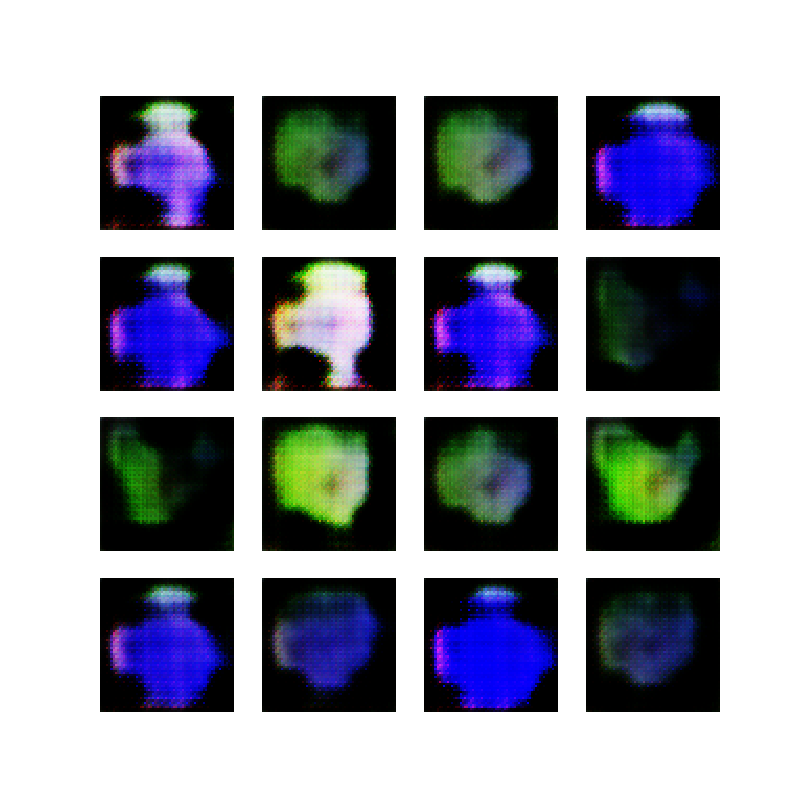
Modifying the above “border collie puppies” example to include a setting (hill) and style (painting) already produces more interesting outputs on the first try:


The keyword “painting” is part of the reason that the images look like actual paint strokes. The border collie dog is still not looking very good, but because the final image is a bit more abstract, it does not matter so much.
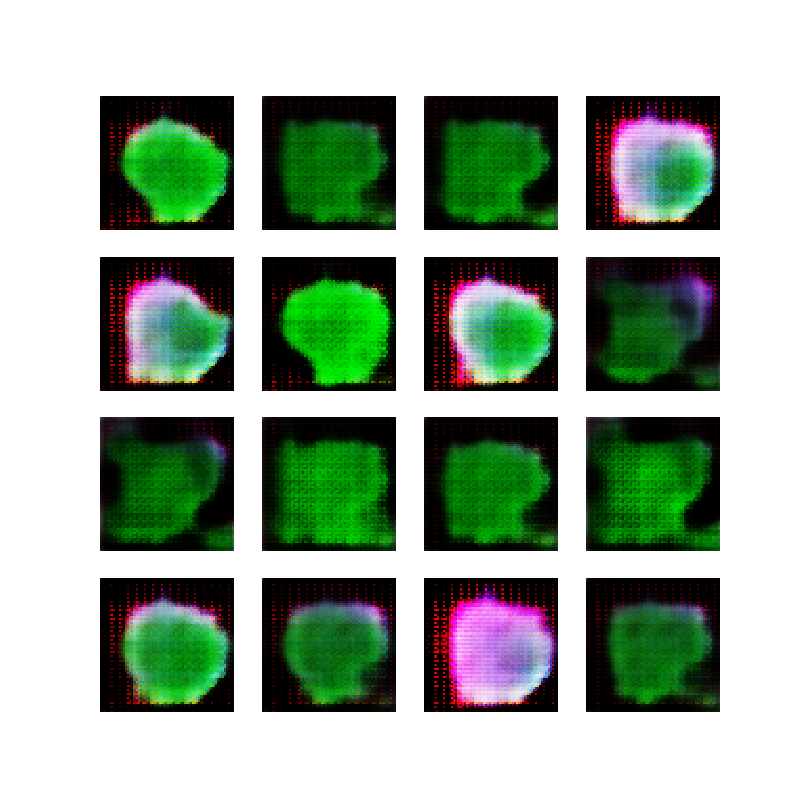
Changing “painting” to “pencil drawing” gives slightly different results. Notice that the texture is less paint-brush and more pencil-like (if you squint a little), and we also get what appears to some sort of text (no idea why):


This way of changing the prompt slightly is quite fun (and time consuming), and people have come up with all sorts of tricks. I am, for example, quite fascinated by the “cyberpunk” aesthetic which I first saw from Rivers Have Wings as well, although that example is using a different generator than VQGAN.
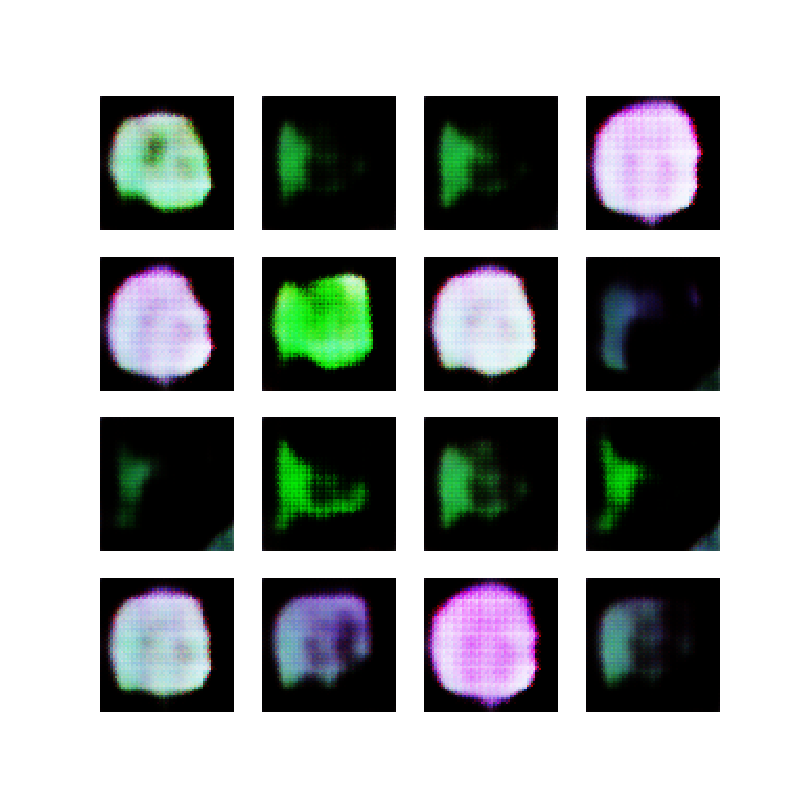
Cyberpunk does not seem to work very well for the existing border collie prompt though, at least not without further tweaking:


It works better for cities:


You can probably see where this is going: Down a rabbit-hole of experimentation.
At this point, it is worth backtracking a bit and mention that there are still simple input prompts (without a specified style) that produce fun outputs. Here are two examples of “a unicorn”:


But to me, the most fun comes from using slightly longer texts to see what comes out of it.
One idea I am playing around with is to take text from other sources and see what the networks come up with. For example, how about the legendary, somewhat-improvised, “tears in the rain” monologue from Rutger Hauer in Blade Runner. To jolt your memory:
I’ve seen things you people wouldn’t believe. Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhäuser Gate. All those moments will be lost in time, like tears in rain. Time to die.
Roy Batty / Rutger Hauer – Blade Runner
If there was ever a quote that deserved to be illustrated, it is this one. Let us try it, but only include the middle part, i.e. “Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhäuser Gate”:

Ok, well, that’s not really coherent is it? It looks like a collage of a battle ship, laser beam, fire, water and starry sky just mixed randomly together. A bit disappointing, but as I mentioned above, the style is often quite important.
And looks what happens when we simply add “science fiction painting” to the prompt:
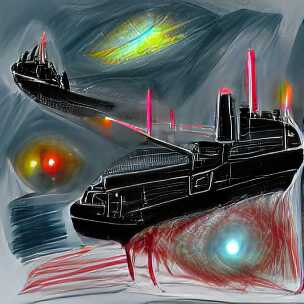

Wow, that is quite different. Personally, I find this very satisfying to look at. I would probably even hang one of these on my wall!
As a side-note, I often find the outputs of the early iterations quite interesting to look at as well. The above images are from the 500th iteration of the generation, but already after 50 iterations, they both have a certain artistic quality to them, especially the second one which I like better than the final output (look at those colors!):


Roy Batty was an AI right? What if we take a modern-day “AI” and produce some text, then use this as a prompt to our image generator.
Using the gpt-neo-1.3B text generator with the text seed “The sky”, here are two example outputs:
The sky was like a black cloud, and a man was standing there, his eyes blue and staring.
gpt-neo-1.3B with seed text “The sky”
The sky was clear. A blackbird had come, had flown into the room and was now looking up at the ground.
gpt-neo-1.3B with seed text “The sky”
In both cases, I added “painting” as style since that seem to work quite well in general.


Ok, so it chose to ignore the “man was standing there” part but at least it generated an eye surrounded by blue. And it depicted a black cloud and clear sky in both cases, as well as the outline of a blackbird.
All I did here was come up with “The sky” and through a series of steps, the neural networks did the rest. This idea of almost 100% AI generation of related text and images is quite fascinating to play around with.
On that note, I will end the post here and continue down the rabbit-hole for a bit longer. Here are two renditions of “a drawing of me going down a rabbit-hole” and two where I added “psychedelic surrealism” to the prompt, because why not.




Goodbye.
(All the images in this post are generated using default settings from this generator script. They are not hand-curated, i.e. they represent more-or-less the first output for each of the prompts. With a bit of curation, and experimentation, your results will be much better, as demonstrated by other authors.)