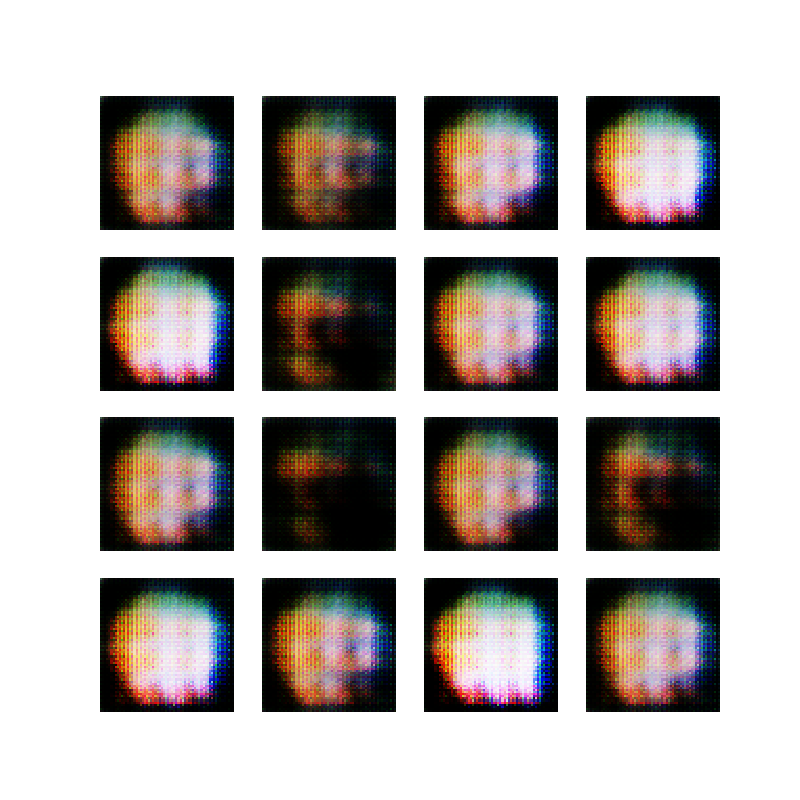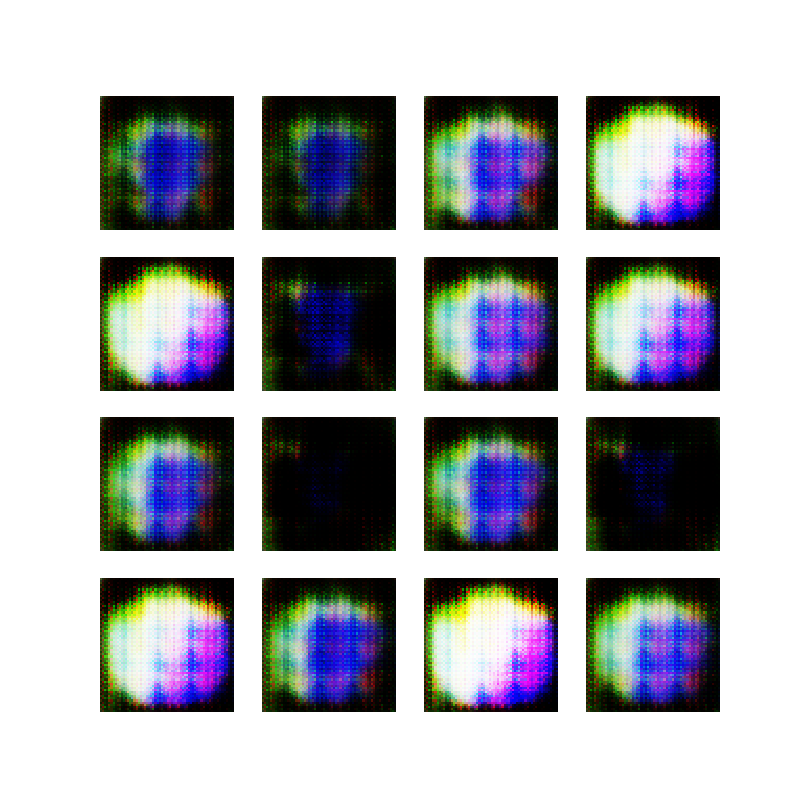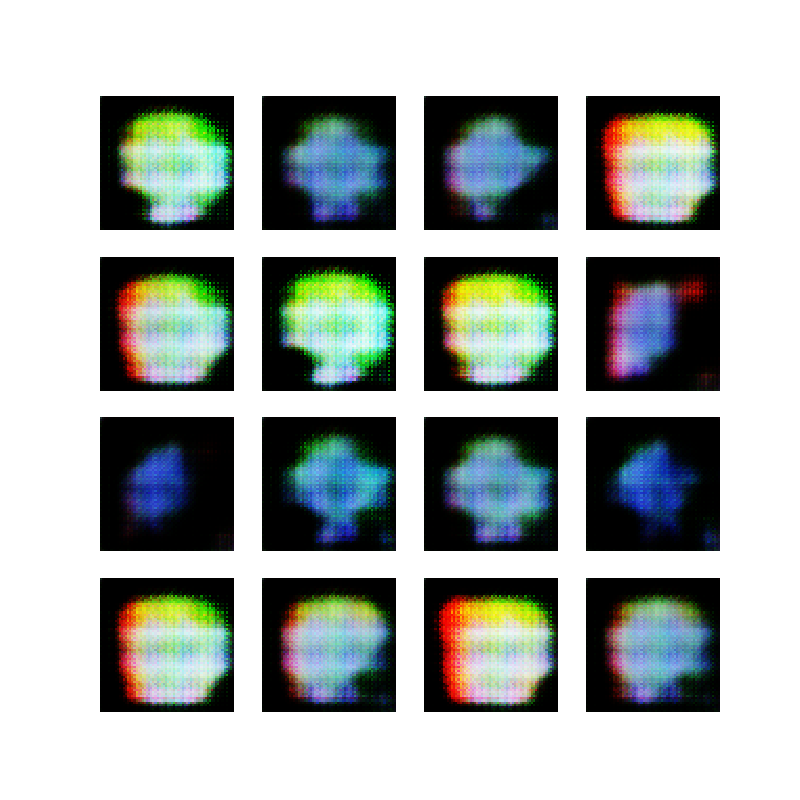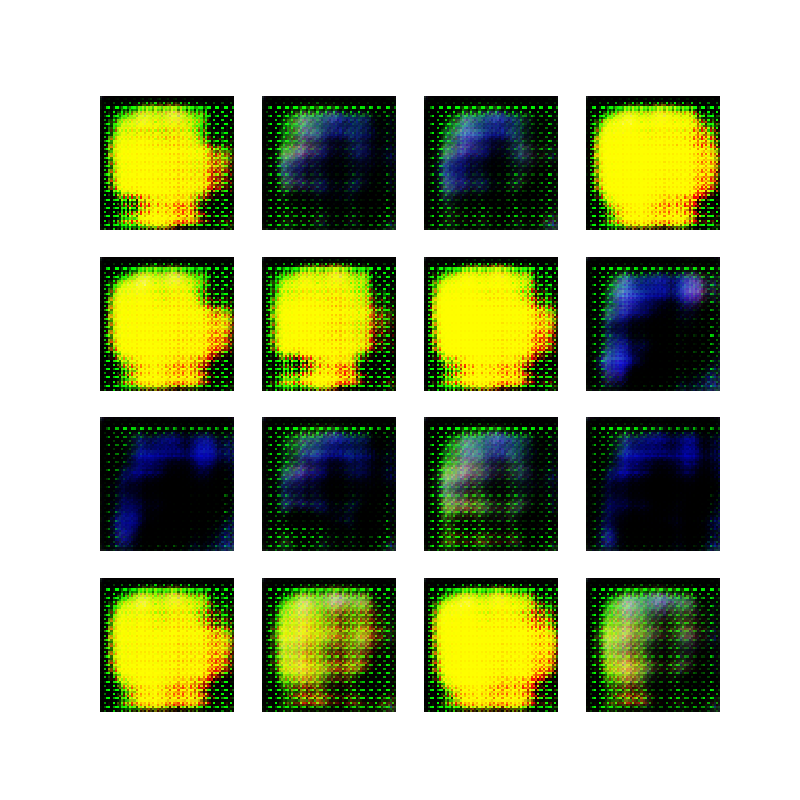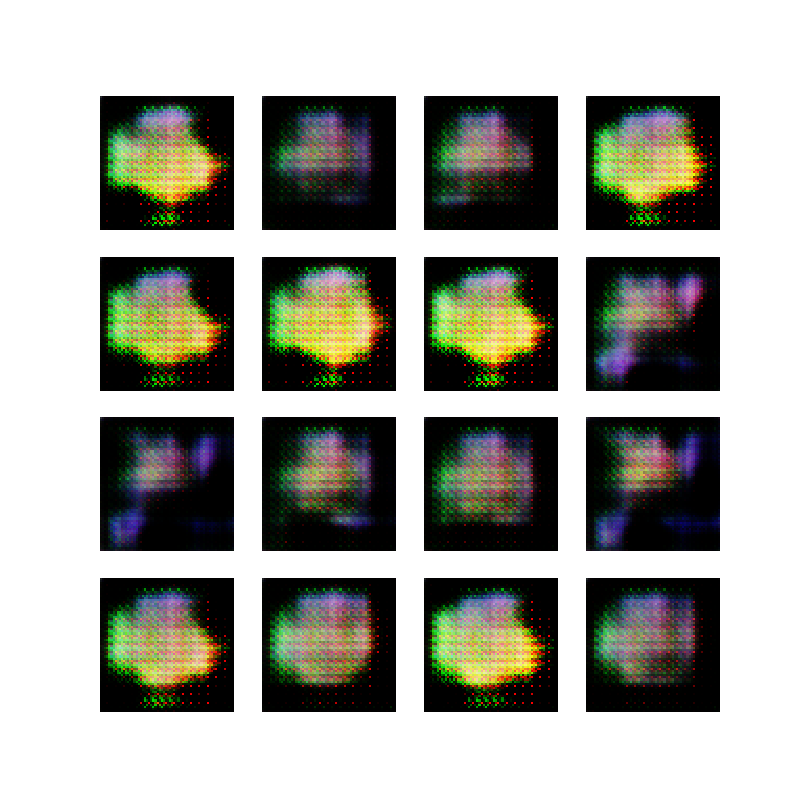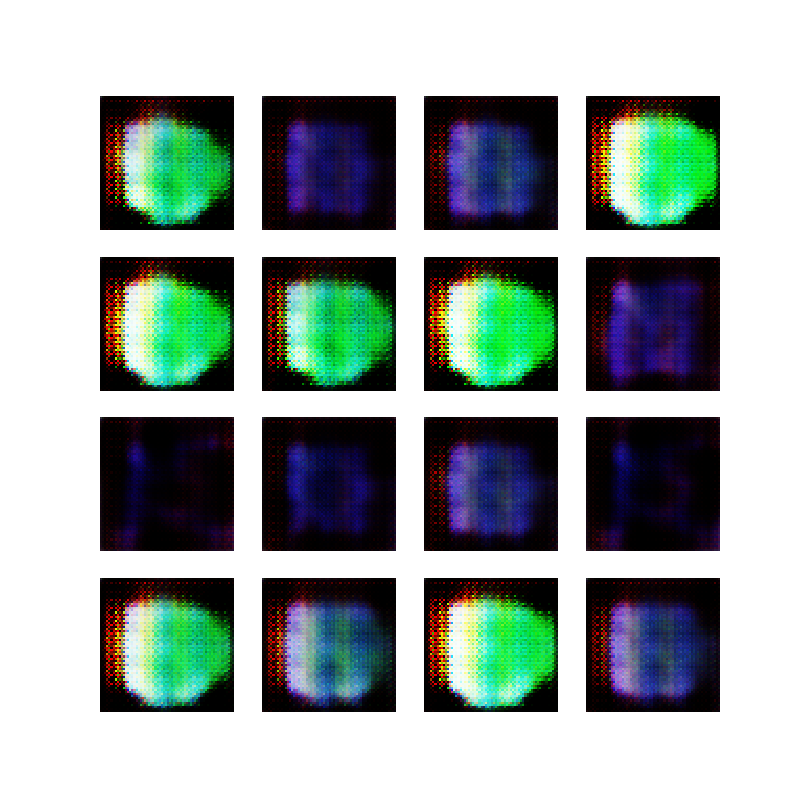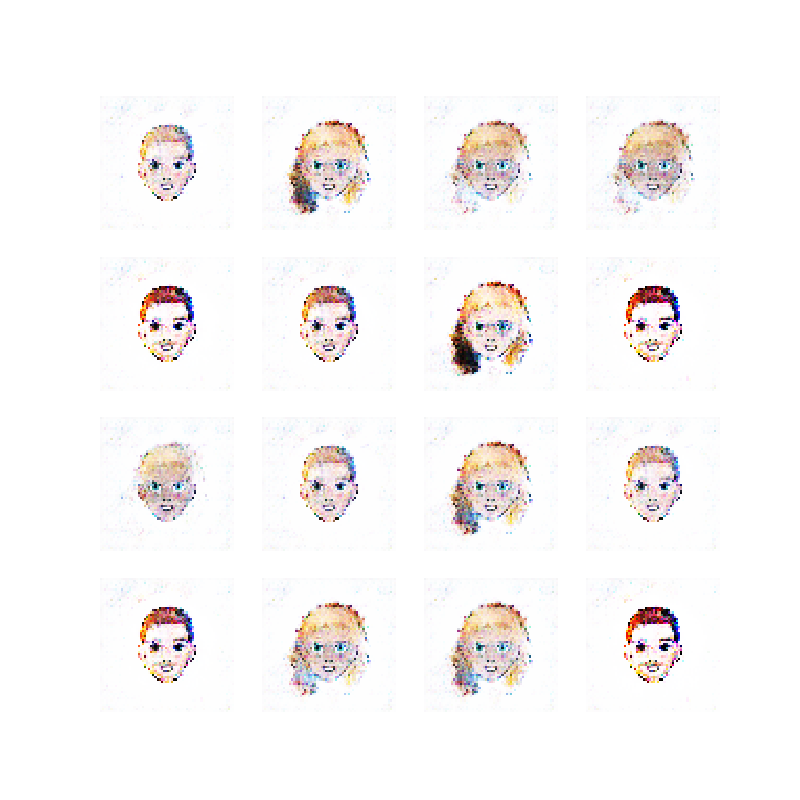As part of a recent talk I did about my now-quite-old lyrics generator, I used the opportunity to update the code a bit and share a few of the trained models, including the world famousGene Lyrica One.
The new “rock” models have similar performance to Gene Lyrica One, but subjectively seemed to be slightly more interesting in some cases. The output is still nonsensical and the same words and sentences are often repeated multiple times, so needless to say I have still not been able to make good progress here.
During the talk, I was also made aware of another cool project which is much more comprehensive than mine, these lyrics do not exist, so that is worth mentioning here as well.
And of course, I can’t post something about the lyrics generator without any lyrics. This one came about in multiple steps:
I used the seed text “hello world is a dream” which was the title of the original blog post. The next sentence “happiness is the one” was then generated along with a bunch of subsequent nonsense.
The two sentences fed into the generator again and it produced “the world was my world”.
Repeat this process a few times…
hello world is a dream happiness is the one the world was my world who would be me
give me all the other day just like a star you were high
Today, I ran through the image captioning tutorial from Tensorflow, because why not. I trained it on a reduced set of 5000 images compared to the tutorial, but otherwise the code is identical.
The purpose of the model is to look at an image and predict a caption for the image, e.g. “man sits next to computer” if the model was looking at me right now.
The results are quite hilarious at this point, and it has given me some ideas for future development that could potentially delight or confuse.
Anyway, for now, here is a caption that is as close to being accurate as I could get today. It’s a picture of Mila, my dog, with the predicted caption “a little dog sitting on dirt field”. Not too bad.
Best predicted caption: a little dog sitting on dirt field
The model has a bit of randomness in its output, so the same image might produce multiple different results. For example, the image above also produced “a dog is surfing on a field with it’s toppings in front of grass” as well as the completely nonsensical “a fire up of a green grass next to a grass in a grassy field”.
I also tried a few other images, but I am a too lazy to look up the proper attribution for including them in this post, so here is another image of Mila with the strange caption “a dog that is standing in tall grass in the grassy field with a large dog and white dog is standing in a grassy field next to a tree”
Best predicted caption: a dog that is standing in tall grass in the grassy field with a large dog and white dog is standing in a grassy field next to a tree
There is also the slightly more boring “a dog standing in front of a grass” and my personal favorite (although it’s a bit disturbing) “a dressed dog in a field eaten horse to enjoy zebras grass in the grass”.
That is it for now. Not much content here, but I felt like writing a post. Stay tuned for possibly more silliness when the spark of energy hits.
I found these lyrics hidden away in my notes. They were created using my updated lyrics generator earlier this year after retraining the neural network using a sentence embedding instead of a word embedding (lyrics generator code). I guess I was waiting to publish it as part of a larger post. No need. This masterpiece stands on its own :-)
hello world
a mighty mighty mighty mighty mighty mighty a world
world world mighty
and mighty mighty mighty mighty
all mighty mom mighty
babies mom the mom
mom
roman you roman mom
mother plastic cat’s roman roman
the pagan pagan pagan pagan pagan pagan pagan pagan pagan i pagan oh dear and dear
You might have heard of Deepfakes, which are images or videos where someone’s face is replaced by another person’s face. There are various techniques for creating Deepfakes, one of them being Generative Adversarial Networks (GANs).
A GAN is a type of neural network that can generate realistic data from random input data. When used for image generation, a generator network creates images and tries to fool a discriminator network into believing that the images are real. The discriminator network gets better at distinguishing between real and fake images over time, which forces the generator to create better and better images.
I wanted to play around with GANs for a while, specifically for generating small cartoon-like images. This post is a status update for the project so far.
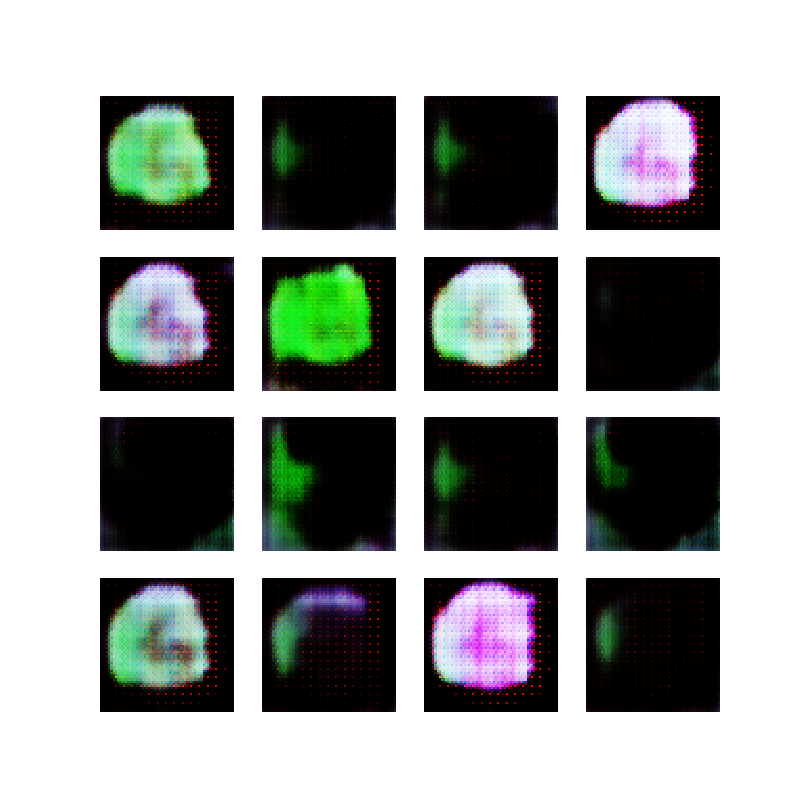
Here is the code, and here are 16 examples of images generated by the current state of the network:
16 cartoon faces generated by a GAN
DCGAN Tutorial and drawing ellipses
There are many online tutorials on how to create a GAN. One of them is the DCGAN tutorial from the Tensorflow authors. This tutorial was my starting point for creating and training a GAN using the DCGAN (deep convolutional GAN) architecture.
In the tutorial, the authors train the GAN to generate hand-written digits, based on the famous MNIST dataset. Instead of creating hand-written-number-lookalikes, I wanted to see if I could generate simple shapes like these ellipses:
Color ellipses used for input
I thought these shapes would be a trivial task for the GAN to generate, but I was of course mistaken.
After implementing the DCGAN network based on the DCGAN tutorial, my first attempt that actually did something produced color in some kind of shape but not actual ellipses.
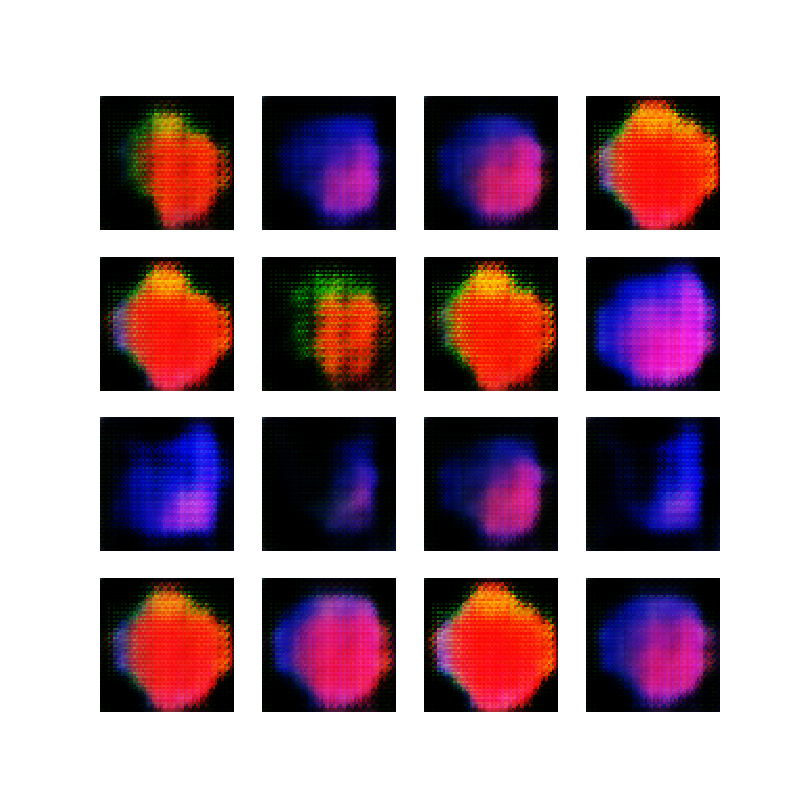
A note on the images shown throughout this post: Let’s say we have 10 thousand images in our dataset (in this case 10 thousand images of an ellipse). One epoch consists of running through all these images once and a network is trained for 50 epochs. At the end of each epoch, an image is captured based on 16 sample inputs to the generator. These inputs stay the same during training. Thus, we have 50 images (one for each epoch) with 16 generated samples when the network is done training, and we are ideally interested in seeing these 16 images get more realistic over time.
The video below shows the evolution of one of these network training sessions. The video is stitched together from the 50 epoch images. Notice that at the beginning of training, the output of the generator is a gray blob which is the random data. Over time, some colors emerge, until training collapses in the end and it just generates white backgrounds :-)
First attempt at making ellipses with a GAN
Ellipses in opaque black and white
Taking a step back and reviewing the tutorial again, I took note of a few things that I did not pay attention to initially:
The tutorial uses white, opaque digits on a black background. I was using unfilled (not opaque) ellipses on a white background.
The images are only black and white (grayscale). I was using many colors.
The MNIST dataset consists of 60 thousand examples. I was using a few hundred images.
If the goal of the generator is to fool the discriminator, but the images of ellipses are actually mostly white background with a little bit of color, it makes somewhat intuitive sense that the generator ends up just drawing white backgrounds as seen in the video above.
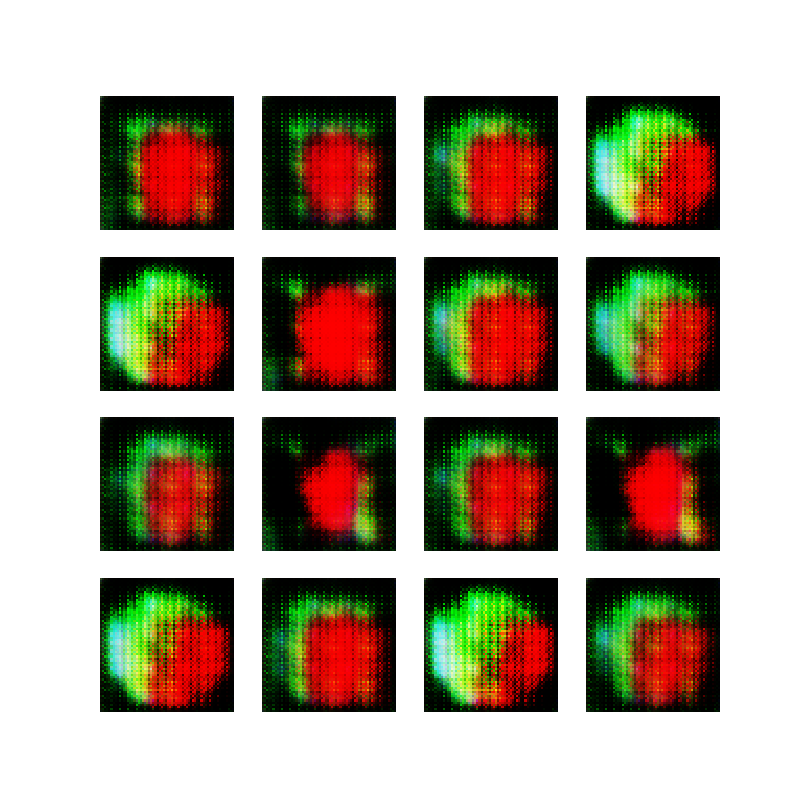
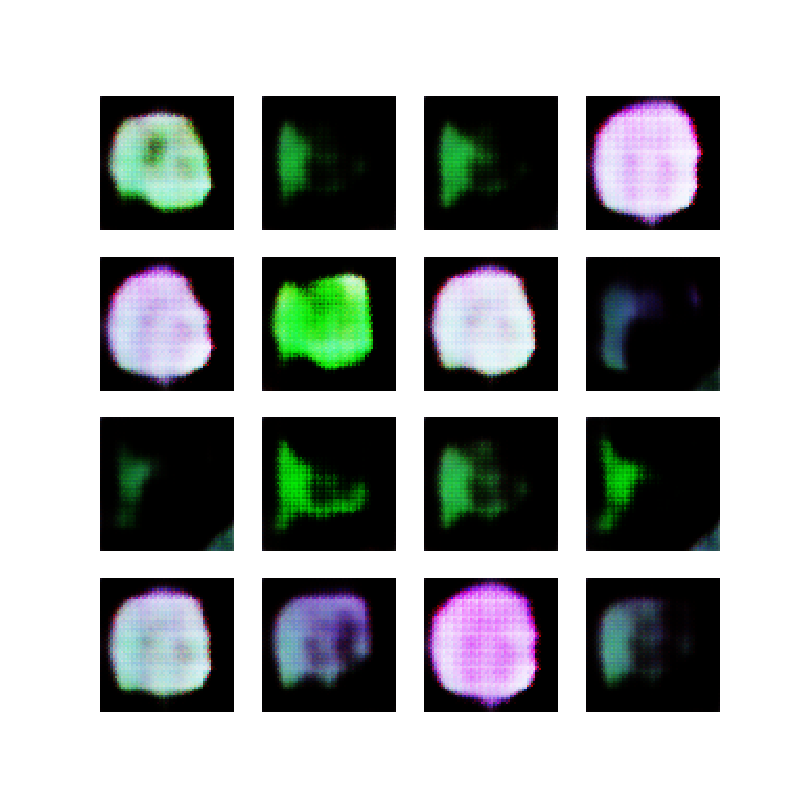
With this in mind, I created 10 thousand opaque white ellipses on a black background, just to prove that the network was indeed working. Here are some examples:
Opaque ellipses, black and white
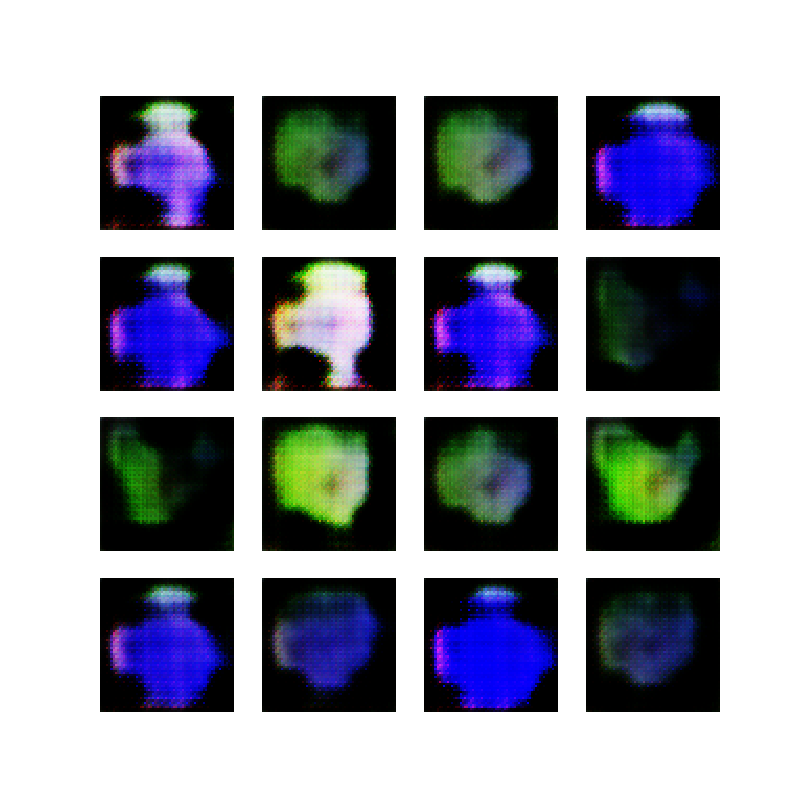
The result from doing this was much better, and the generator ended up creating something that resembles circles:
Second attempt at making ellipses with a GAN
Wow, I created a neural network with 1 million parameters that can generate white blobs on a black background *crowd goes wild and gives a standing ovation*.
Sarcasm aside, it is always a good feeling when the network finally does something within a reasonable timeframe (it took about a minute to train this network).
Deeper, wider, opaque, color
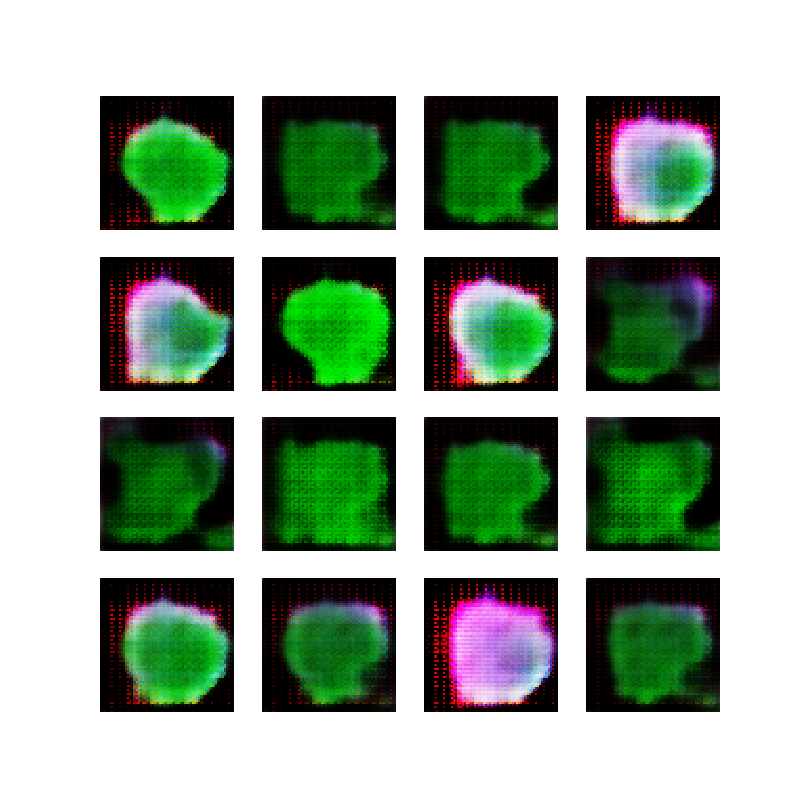
After the “success” of the black and white ellipses, I started reviewing some tips on how to tweak a GAN (see references at the bottom of post). Without going into too much detail, I basically made the neural network slightly deeper (more layers) and slightly wider (more features) and switched back to using random colors for the ellipses, while keeping them opaque.
Here are some examples of the input ellipses:
Opaque ellipses, with color
After training the network with these images, it was interesting to see the 16 generated samples converge to colored blobs and then change dramatically between epochs. I think this is what is known as “mode collapse” and is a known issue/risk when training GANs:
Each iteration of [the] generator over-optimizes for a particular discriminator, and the discriminator never manages to learn its way out of the trap. As a result the generators rotate through a small set of output types. This form of GAN failure is called mode collapse.
Mode collapse is most obvious when viewing the epoch images individually, so rather than stitch them together into a video, I have included 50 images below. Notice that after about 20-25 epochs, the output starts to resemble colored ellipses, and all epochs after that do not seem to improve much:
I must admit, I think there’s a certain beauty to these generated images, but to be honest, it is still just randomly colored blobs, and they could be generated with much simpler algorithms than this beast of a neural network.
Generating cartoon avatars
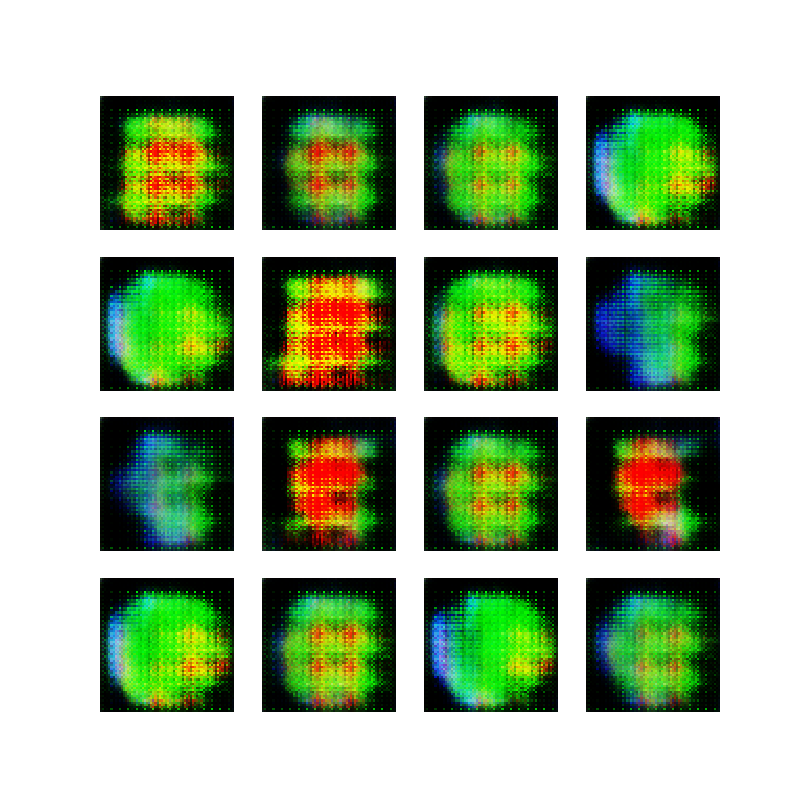
Instead of continuing to tweak the ellipses-generating network, I wanted to see if I could generate more complex images. My original idea was to generate cartoon like images, and to my great delight, Google provides the Cartoon Set, a dataset consisting of thousands of cartoon avatars, licensed under the CC-BY license.
You have already seen an example result of using this dataset at the top of this post. Here are the 50 epoch images from training the network on the small version of the dataset (10 thousand images). Notice that the network starts to create face-like images after just a few epochs, and then starts cycling the style of the face, probably due to the above mentioned mode collapse.:
This is as far as I got currently. I would like to create a little web app for generating these images in the browser, but that will have to wait for another day. It would also be nice to be able to provide the facial features (hair color, eye color, etc.) as inputs to the network and see how that performs.
To keep my motivation up though, I think I need to switch gears and try something else for now. This was fun! :-)
Neurons Spike Back (https://neurovenge.antonomase.fr/) was featured in the latest data science weekly newsletter. I would normally pass on such long articles, but the history of AI is interesting, so I gave it a shot. Reading the paper felt like a marathon, and I only completed it through sheer force of will, lots of coffee, and because it is cold and raining outside.
The article is very difficult to read (at least for me), not because it is filled with theory, but because the language is dry and academic, and it tries to condense decades of history around the research of AI into a fairly short (given the topic) article that discusses two opposing sides of research and thought: connectionist and symbolic AI.
Despite my warning above, if you have the patience, I found it to be a fairly good overview of how we ended up where we are today with deep learning dominating the state of the art for AI in many fields.
I found it particularly interesting to learn about the Mark I, a hardware neural network constructed during the 1960’s for simple object recognition. It is a good reminder that the concepts we are using today have been around for a very long time, and I often find that knowing a bit of the history behind them help understand what we are doing in the present.