Generating song lyrics using neural networks… that sounds cool! Those were my thoughts on an evening in the recent past, so I started experimenting with the idea.
I decided to name the neural network that came out of this project Gene Lyrica One, a very AI-sounding name (it is “the year of AI” after all). But before we get into the details of how Gene was born, let’s set the stage for this blog post with Gene’s unique take on the classic “hello world”:
hello world is a dream
i know when i been like your love
and i can’t go home
i can’t cry
i don’t want to see
i don’t know why i can’t run
i got me
i got the way you know
i want to feel my love
i want to go
i need you
and i want to feel so good
i want to get it and i can’t see
i’m gonna stop if i had it
i can’t really want to see
Gene Lyrica One
The neural network is given some initial text, called the seed text, and then the network creates new lyrics based on this text. As mentioned above, the seed text for these lyrics were “hello world” which, given the subject matter, makes sense on multiple levels.
If you want to create your own lyrics, you can try it out here, and the code that generated the network can be found on GitHub.
In the following sections, I will describe the process that led to Gene Lyrica One, including more lyrics from Gene as well as other networks that were part of the experiment.
I have no clue
i have no clue
i want to lose the night
and i’m just a look in your mind
but i know what you want to do
all the way
i gave you love
and i can think you want to
Gene Lyrica One
Generating lyrics is not a walk in the park, and I have not quite cracked the nut yet. To be honest, I would say I generally have no clue what I am doing.
I know where I started though: To get a feeling for how to “predict language” with a neural network, I created neural networks to generate text based on two different techniques:
- Given a sequence of words, predict another full sequence of words.
- Given a sequence of words, predict just one word as the next word.
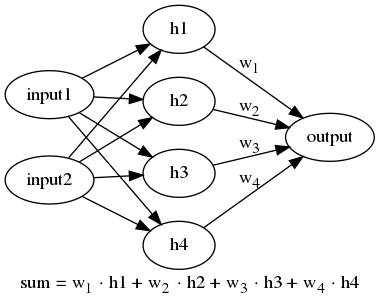
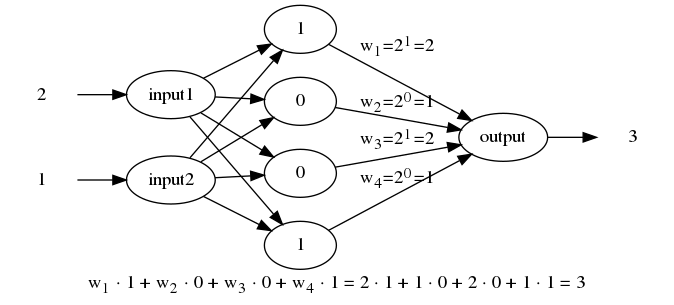
The second kind of model (sequence-to-single-word) is the one that conceptually and practically was easiest for me to understand. The idea is this: For an input sentence like “all work and no play makes jack a dull boy”, we can split the sentence into small chunks that the neural network can learn from. For example “all work and no” as input and “play” (the next word) as output. Here is some code that does just that.
With the basic proof-of-concept architecture in place, I started looking for a dataset of song lyrics. One of the first hits on Google was a Kaggle dataset with more than 55 thousand song lyrics. This felt like an adequate amount so I went with that.
New Lines
new lines
gotta see what you can do
oh you know
Gene Lyrica One
Lyrics consist of a lot of short sentences on separate lines, and while the texts on each line are often related in content, they do not necessarily follow the same flow as the prose in a book.
This led to two specific design decisions for creating the training data. First, newline characters (\n) are treated as words on their own, which means that a “new line” can be predicted by the network. Second, the length of the input sequences should not be too long since the context of a song is often only important within a verse or chorus. The average length of a line for all songs happens to be exactly 7 words, so I decided to use 14 words for the input sequences to potentially capture multiline word relationships.
A few other decisions worth mentioning:
- Words are not pre-processed. This means that e.g. running, runnin, and runnin’ will be treated as three different words.
- Words are not removed or cleaned. For example, the word “chorus” sometimes appear in the dataset to mark the beginning of the song’s chorus.
Well Known With a Twist
well known with a twist for the bed
i got the
oh oh
what you want to do
i’m goin’ down
Gene Lyrica One
The first attempt at training the network yielded some funny results. Because there were hundreds of thousands of parameters to tune in the network, training was extremely slow, so I initially tested it on just the first 100 songs in the dataset. Because of alphabetical ordering, these all happened to be Abba songs.
The final accuracy of the network was somewhere around 80%. One way to interpret this is to say that the network knew 80% of the Abba songs “by heart”. Thus, the network was creating “Abba songs with a twist”. For example, it created the verse:
so long see you baby
so long see you honey
you let me be
Baba Twist
The Abba song “So long” has the phrase “so long see you honey” so it improvised a little bit with the “so long see you baby” (“you baby” appears in a different Abba song “Crying Over You” which probably explains the variation). Or how about:
like a feeling a little more
oh no waiting for the time
if you would the day with you
’cause i’m still my life is a friend
happy new year
happy new year
happy new year
……
[many more happy new years] :-)
Baba Twist
which is probably “inspired” by the Abba song “Happy New Year”. The network was overfitting the data for Abba, which turned out to be fun, so this was a promising start.
Too much information
too much information
i can’t go
Gene Lyrica One
With decent results from Baba Twist (the Abba-network), it was time to try training the network using all 55 thousand songs as input data. I was excited and hopeful that this network would be able to create a hit, so I let the training process run overnight.
Unfortunately, my computer apparently could not handle the amount of data, so I woke up to a frozen process that had only finished running through all the songs once (this is called one epoch, and training often requires 50 or more epochs for good results).
Luckily, the training process automatically saves checkpoints of the model at certain time intervals, so I had some model, but it was really bad. Here is an example:
i don’t know what i don’t know
i don’t know what i don’t know
i don’t know what i don’t know
Tod Wonkin’
Not exactly a masterpiece, but at least Tod was honest about its situation. Actually, “I don’t know what I don’t know” was the only text Tod produced, regardless of the seed text.
In this case, I think there was too much information for the network. This feels a bit counter-intuitive. We usually seem to always want more data, not less, but for a small hobby project like this, it probably made sense to reduce the data size a bit to make the project more manageable and practical.
Famous Rock
famous rock are the dream
chorus
well i got a fool in my head
i can be
i want to be
i want to be
i want to be
i want to be
Gene Lyrica One
After the failure of Tod Wonkin’, I decided to limit the data used for training the network. I theorized that it would be better to only include artists with more than 50 songs and have a smaller number of artists in general, because it would potentially create some consistency across songs. Once again, this is a case of “I have no clue what I’m doing”, but at least the theory sounded reasonable.
A “top rock bands of all time” list became the inspiration for what artists to choose. In the end, there were 20 rock artists in the reduced dataset, including Beatles, Rolling Stones, Pink Floyd, Bob Dylan etc. Collectively, they had 2689 songs in the dataset and 16389 unique words.
The lyrics from these artists are what created Gene Lyrica One.
It took some hours to train the network on the data, and it stopped by itself when it was no longer improving, with a final “accuracy” of something like 22%. This might sound low, but high accuracy is not desirable, because the network would just replicate the existing lyrics (like Baba Twist). Instead, the network should be trained just enough that it makes sentences that are somewhat coherent with the English language.
Gene Lyrica One felt like an instant disappointment at first, mirroring the failure of Tod Wonkin’ by producing “I want to be” over and over. At the beginning of this post, I mentioned Gene Lyrica One’s “Hello World” lyrics. Actually, the deterministic version of these are:
hello world is a little man
i can’t be a little little little girl
i want to be
i want to be
……
[many more “i want to be”]
Gene Lyrica One
At least Gene knew that it wanted to be something (not a little little little girl, it seems), whereas Tod did not know anything :-)
The pattern of repeating “I want to be” was (is) quite consistent for Gene Lyrica One. The network might produce some initial words that seems interesting (like “hello world is a little man”), but it very quickly gets into a loop of repeating itself with “i want to be”.
Adding Random
adding random the little
you are
and i don’t want to say
i know i don’t know
i know i want to get out
Gene Lyrica One
The output of a neural network is deterministic in most cases. Given the same input, it will produce the same output, always. The output from the lyric generators is a huge list of “probabilities that the next word will be X”. For Gene Lyrica One, for example, the output is a list of 16389 probabilities, one for each of the available unique words.
The networks I trained were biased towards common words like “I”, “to”, “be”, etc. as well as the newline character. This explains why both Gene Lyrica One and Tod Wonkin’ got into word loops. In Gene’s case, the words in “I want to be” were the most likely to be predicted, almost no matter what the initial text seed was.
Inspired by another Kaggle user, which in turn was inspired by an example from Keras, I added some “randomness” to the chosen words in the output. The randomness could be adjusted, but adding too much of it would produce lyrics that do not make sense at all.
All the quotes generated by Gene Lyrica One for this post have been created using a bit of “randomness”. For most of the sections above, the lyrics were chosen from a small handful of outputs. I did not spend hours finding the perfect lyrics for each section, just something that sounded fun.
The final trick
the final trick or my heart is the one of a world
you can get out of the road
we know the sun
i know i know
i’ll see you with you
Gene Lyrica One
A few months ago, TensorFlow.js was introduced which brings machine learning into the browser. It is not the first time we see something like this, but I think TensorFlow.js is a potential game changer, because it is backed by an already-successful library and community.
I have been looking for an excuse to try out TensorFlow.js since it was introduced, so for my final trick, I thought it would be perfect to see if the lyrics generators could be exported to browser versions, so they could be included more easily on a web page.
There were a few roadblocks and headaches involved with this, since TensorFlow.js is a young library, but if you already tried out my lyrics generator in the browser, then that is at least proof that I managed to kind-of do it. And it is in fact Gene Lyrica One producing lyrics in the browser!
This is the end
this is the end of the night
i was not every world
i feel it
Gene Lyrica One
With this surprisingly insightful observation from Gene (“I was not every world”), it is time to wrap up for now. Overall, I am pleased with the outcome of the project. Even with my limited knowledge of recurrent neural networks, it was possible to train a network that can produce lyrics-like texts.
It is ok to be skeptical towards the entire premise of this setup though. One could argue that the neural network is just an unnecessarily complex probability model, and that simpler models using different techniques could produce equally good results. For example, a hand-coded language model might produce text with better grammar.
However, the cool thing about deep learning is that it does not necessarily require knowledge of grammar and language structure — it just needs enough data to learn on its own.
This is both a blessing and a curse. Although I learned a lot about neural networks and deep learning during this project, I did not gain any knowledge regarding the language structure and composition of lyrics.
I will probably not understand why hello world is a dream for now.
But I am ok with that.