Some weeks ago, I was at a get together with my old university friends that we call “the hack day”. It usually revolves around drinking lots of coffee and soft drinks, eating loads of chips and candy, as well as working on the occasional masterpiece project like Zombie Hugs.
At the end of the day, one of us (I cannot remember who now) mentioned how useful it would be to have a neural network that could add numbers together.
The remark was meant as a joke, but it got me thinking, and on the way home on the train, I pieced together some code for creating a neural network that could perform addition on two numbers between 0 and 9. Here’s the original code.
Warning: The rest of this post is probably going to be a complete waste of your time. The whole premise for this post is based on a terrible idea and provides no value to humanity. Read on at your own risk :-)
Making addition more interesting
It is worth mentioning that it is actually trivial to make a neural network add numbers. For example, if we want to add two numbers, we can construct a network with two inputs and one output, set the weights between input and output to 1, and use a linear activation function on the output, as illustrated below for 20 + 22:

It is not really the network itself that performs addition. Rather, it just takes advantage of the fact that a neural network uses addition as a basic building block in its design.
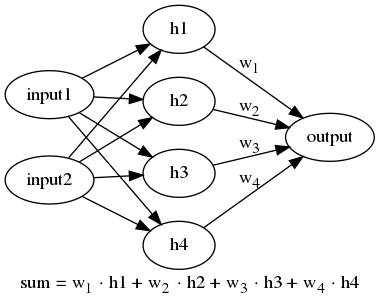
Things get more interesting if we add a hidden layer and use a non-linear activation function like a sigmoid, thereby forcing the output of the hidden layers to be a list of numbers between 0 and 1. The final output is still a single number which is a linear combination of the output of the hidden layer. Here is a network with 4 hidden nodes as an example:
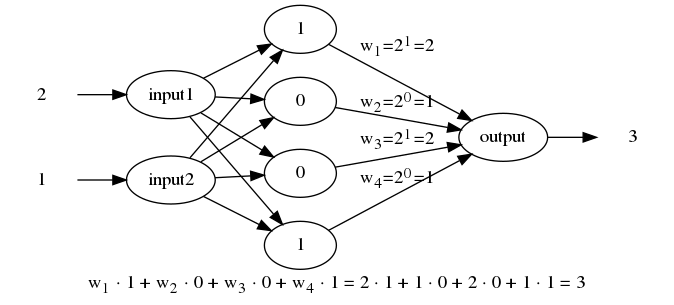
When we ask a computer to perform 2 + 1, the computer is really doing 10 + 01 (2 is 10 in binary and 1 is 01). I had this thought at the back of my mind, that the neural network might “discover” an encoding in the hidden layer which was close to the binary representation of the input numbers.
For example, for the 4-node hidden layer network illustrated above, we could imagine the number from input1 being encoded in h1 and h2 and the number for input2 being encoded in h3 and h4.
For 2 + 1, the four hidden nodes would then be 1, 0, 0 and 1, and the final output would convert binary to decimal (2 and 1) and add the numbers together to get 3 as result:
Since the hidden nodes are restricted to be between 0 and 1, it seemed intuitive to me that a binary representation of the input would be a very effective way of encoding the data, and the network would thus discover this effective encoding, given enough data.
False assumptions
To be honest, I did not think this through very thoroughly. I should have realized that:
- The sigmoid function can produce any decimal number between 0 and 1, thus allowing for a very wide range of values. Many of these would probably work well for addition, so it is unlikely it would “choose” to produce zeros and ones only.
- It is unclear how a linear combination of input weights would produce the binary representation in the first place.
That second point is important. For the 2-bit (2 nodes) encoding, we would have to satisfy these equations (where S(x) is the sigmoid function and w1 and w2 are the weights from the input node to the 2-node hidden layer):
| Input number | Binary encoding | Equations |
| 0 | 0,0 | S(w1 · 0) ≈ 0 S(w2 · 0) ≈ 0 |
| 1 | 0,1 | S(w1 · 1) ≈ 0 S(w2 · 1) ≈ 1 |
| 2 | 1,0 | S(w1 · 2) ≈ 1 S(w2 · 2) ≈ 0 |
| 3 | 1,1 | S(w1 · 3) ≈ 1 S(w2 · 3) ≈ 1 |
Which weights w1 and w2 would satisfy these equations? Without providing proof, I actually think this is impossible. For example, both S(w2 · 1) ≈ 1 and S(w2 · 2) ≈ 0 cannot be satisfied at the same time. Disregarding the sigmoid function, this is like saying 2x = 0 and x = 1 which is not possible.
The Experiment
Regardless of the bad idea, false assumption or whatever, I still went ahead and made the following experiment:
- Use two input numbers.
- Use 1, 2, 4, 8 or 16 nodes in the hidden layer.
- Use mean squared error (MSE) on the predicted sum as loss function.
- Generate 10,000 pairs of numbers and their sum for training data.
- Use 20% of samples as validation data.
- Allow the sum of the two numbers to be at most 4, 8 or 16 bits large (i.e. 16, 256 and 65536).
- Train for at most 1000 epochs.
When measuring accuracy, the predicted number is rounded to the nearest integer and is either correct or not. For example, if the network says 2 + 2 = 4.4, it is considered correct, but if it says 2 + 2 = 4.6, it is considered incorrect. 20% accuracy thus means that it correctly adds the two numbers 20% of the time on a test dataset.
Here is a summary of the accuracy and error of these models:
| Number of hidden nodes | Maximum sum | Accuracy on test data | Error (MSE) |
| 1 | 16 | 20% | 7 |
| 1 | 256 | 1% | 1487 |
| 1 | 65536 | 0% | 1,247,552,766 |
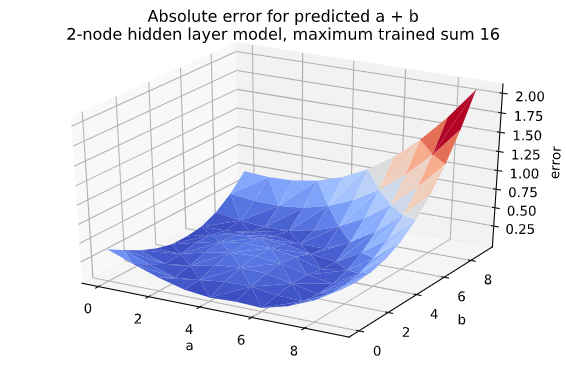
| 2 | 16 | 93% | 0.0 |
| 2 | 256 | 2% | 296 |
| 2 | 65536 | 0% | 1,214,443,325 |
| 4 | 16 | 93% | 0.0 |
| 4 | 256 | 1% | 856 |
| 4 | 65536 | 0% | 1,206,124,445 |
| 8 | 16 | 93% | 0.0 |
| 8 | 256 | 6% | 85 |
| 8 | 65536 | 0% | 1,150,550,393 |
| 16 | 16 | 96% | 0.0 |
| 16 | 256 | 6% | 48 |
| 16 | 65536 | 0% | 1,028,308,841 |
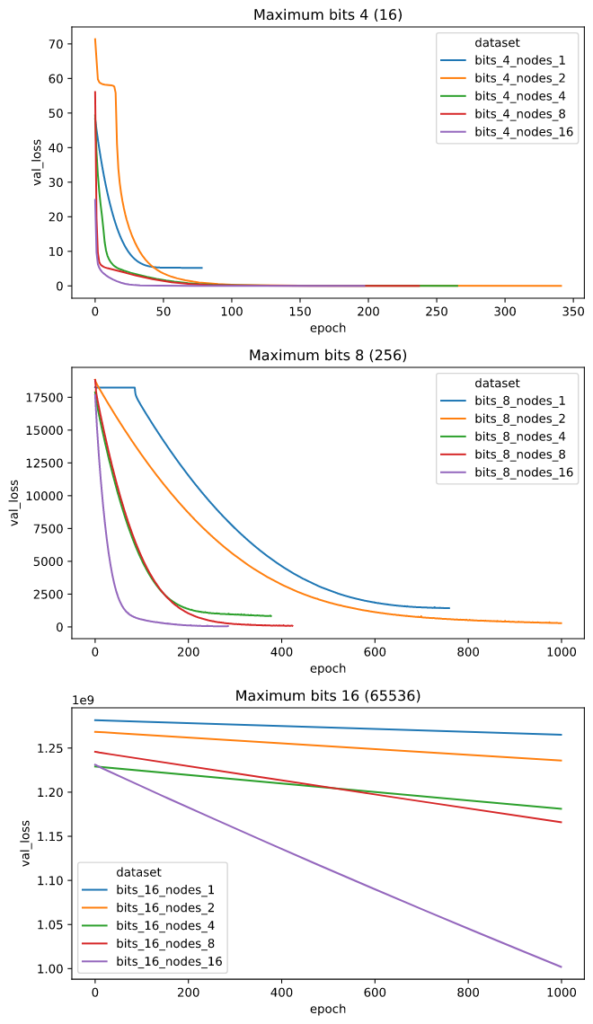
There are a few things that are interesting here:
- The 1-node network cannot add numbers at all.
- Networks with 2 or more hidden nodes get high accuracy when adding numbers with a sum of at most 16.
- All networks perform poorly when adding numbers with a sum of at most 256.
- All networks have abysmal performance for numbers with a sum of at most 65536.
- Adding more hidden nodes improves performance most of the time.
Here is a plot of the validation loss for the different networks after each epoch. Training can stop early if the performance does not improve, which explains why some lines are shorter than others:
Exploring prediction errors
Let us look at the prediction error for each pair of numbers. For example, the 1-node network trained on sums up to 16 has an overall accuracy of 20%. When we add 2 + 2 with this network we get 6.42 so the error is 2.42 in this case. If we try a lot of combinations of numbers, we can plot a nice 3D error surface like this:
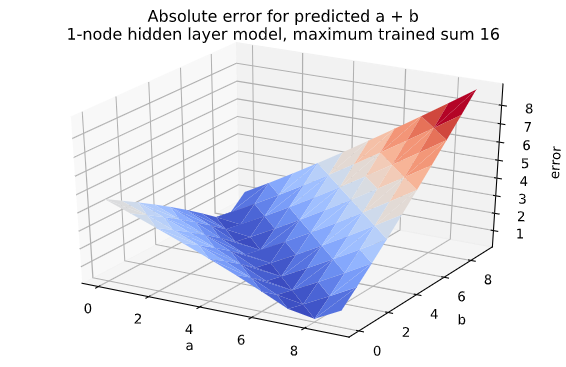
It looks like the network is good at predicting numbers where the sum is 8 (the valley in the chart), but not very good at predicting anything else. The network is probably overfitting to numbers that sum to 8, because the training data has an overweight of samples that sum to 8.
Adding an extra node brings the accuracy up above 90%. The error surface plot for this network also looks better, but both networks struggle with larger numbers:
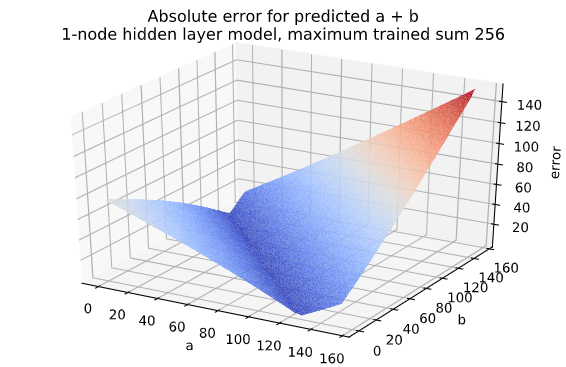
When predicting sums up to 256, the 1-node hidden layer model shows the same error pattern, i.e. a valley (low error) for sums close to 130. In fact, the network only ever predicts values between 78 and 152 (this cannot be seen from the graph), so it really is a terrible model:
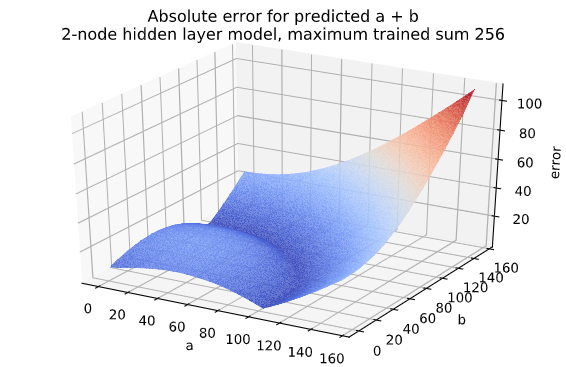
The 2-node hidden layer network does not do much better for sums up to 256 which is expected since the accuracy is just 2%. But it looks fun:
As can be seen in the table above, even the 16-node hidden layer network only had 6% accuracy for sums up to 256. The error plot for this network looks like this:
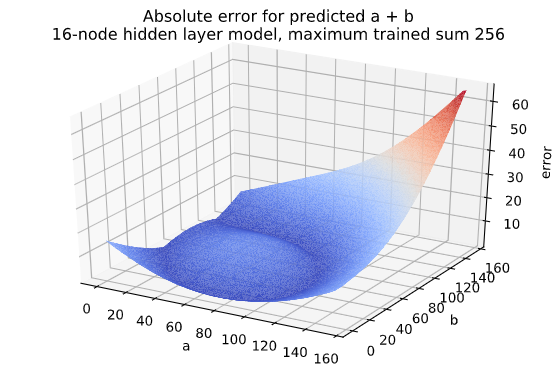
I find this circular shape to be quite interesting. It almost looks like a moat around a hill. The network correctly predicts some sums between 51 and 180, but there is an error bump in the middle.
For example, for the sum 120, 60 + 60 is predicted as 128.8 (error = 8.8), but 103 + 17 is predicted as 119.9 (error = 0.1) which is correct when rounded. The error curve for numbers that sum to 120 is essentially a cross section of the 3D plot where the hill is more visible:
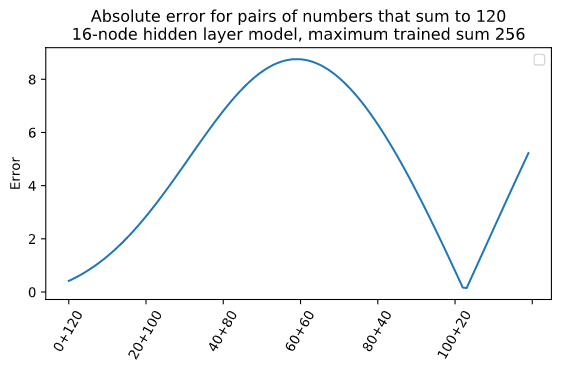
I have no idea why this specific pattern emerges, but I find it interesting that it looks similar to the 2-node network when predicting sums up to 16 (the hill and the moat). A more mathematically inclined person could probably provide me with some answers.
Finally, for the networks that were trained on sums up to 65536, we saw abysmal performance in all cases. Here is the error surface for the 16-node network which was the “best” performing one:
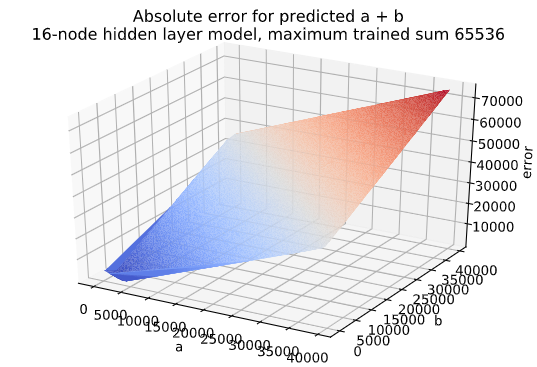
The lowest error this network gets on a test set is the sum 3370 + 329 = 3699 which the network predicts as 3745.5 (error = 46.5).
In fact, the network mostly just predicts the value 3746. As a and b get larger, the hidden layer always produces all 1’s and 0’s (or values very close to 0 and 1), so the final output is always the same. This already starts happening when a and b are larger than around 10 which probably indicates that the network needs more time to train.
The inner workings of the network
My initial interest was in how the networks decided to represent numbers in the hidden layer of the network.
To keep things simple, let us just look at the 2-node hidden layer network on sums up to 16 since this network produced mostly correct sum predictions.
What actually happens when we predict 2 + 2 with this network is illustrated below. The number above an edge in the graph is the weight between the nodes. There is a total of 6 weights for this network (4 from input layer to hidden layer and 2 from hidden layer to output layer):
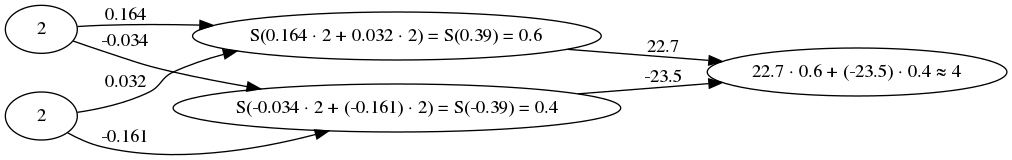
One thing that might be of interest are the final weights 22.7 and -23.5. The way the network sums numbers is to treat the first hidden node as contributing positively to the sum and the second hidden node to contribute negatively. And they are almost the same.
It turns out that the 4-node hidden layer network works the same way. Here, there are 4 weights between hidden layer and output layer, and these are (rounded) 8, 8, 9 and -25. So we still have the large negative weight, but the positive weighting is now split between three hidden nodes with lower values that sum to 25. When calculating 2 + 2, the output of the hidden layer is 0.6, 0.6, 0.6 and 0.4 which is exactly the same as the 2-node network.
The same goes for the 8-node network. The 8 output weights are 3, 3, 3, 3, 4, 5, 5 and -25 (the positive numbers sum to 26). When predicting 2 + 2, the hidden layer outputs 0.6, …, 0.6 and 0.4, same as before.
Once again, I am a bit stumped as to why this could be, but it seems that for this particular case, these networks find a similar solution to the problem.
Conclusion?
If you made it this far, congratulations! I have already spent way more time on this post than it deserves.
I learned that using neural networks to add numbers is a terrible idea, and that I should spend some more time thinking before doing. That is at least something.
The experimentation code can be found here.
Leave a Reply